

Amundsen - Data Catalog Tool
Lyft
Background
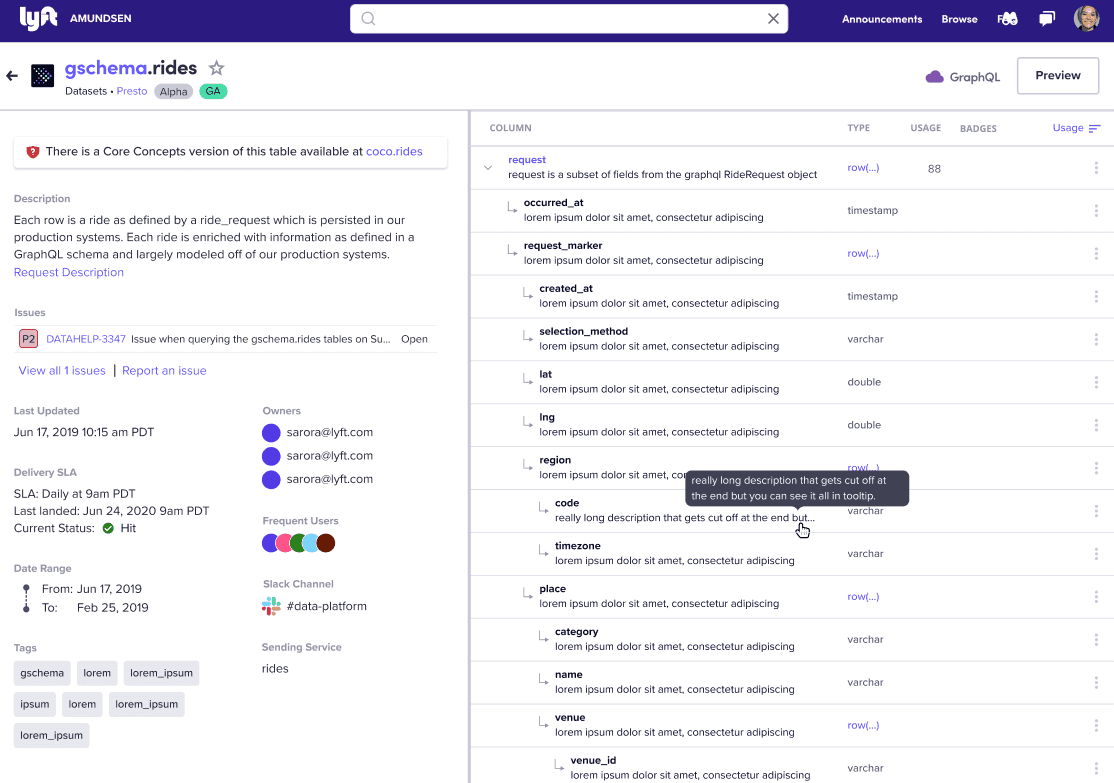
Amundsen is a metadata-driven data tool for improving the productivity of data people (analysts, scientists, engineers, ML modelers) and software engineers when interacting with data. It indexes data resources and page-ranks them to enable search based on metadata and usage patterns.
The project was created at Lyft, used at tens of tech companies, and supports many integrations with tools within the modern data ecosystem.
Role
I joined the team after joining Lyft and took over leading the Frontend side of the development after my onboarding.
During my three-year tenure at Lyft, I had the chance of:
- Setting the direction of the UX and frontend codebase with design docs and code reviews and creating a long-term frontend technical strategy.
- Delivering code that encouraged the team regarding best practices, readability, simple design, reusability, and testing.
- Designing, planning, building, and driving the adoption of Amundsen's features: Announcements, Column Sorting, - Dashboards & more with ReactJS, Sass, Typescript, and Jest.
- Leading frontend planning, milestones, and product and technical roadmaps.
- Shaping and leading the OSS community processes like issue triaging, RFC process, Governance, and assisting the move into Linux Foundation.
Results
As a result, I managed to:
- Contribute to improving Amundsen's customer satisfaction to make it the most appreciated Data tool at Lyft.
- Ensure Amundsen's long-term open-source sustainability
- Enhance shipping velocity, developer experience, observability, and code quality standards
- Cultivate community within the OSS project
- Strengthen five engineers in frontend development through pair programming, technical direction, design, and code reviews.
As of May 2023, Amundsen has more than 3.9K stars on GitHub and has been forked more than 900 times. The project even made it to Thoughtworks Technology Radar on October 2020 in the Platforms category.